Blog #30 - Week of April 5th
I read the third paper that Professor Passonneau pointed me to this week. It was a hefty paper and I will likely have to go back through it to fully understand all parts, but it presented good material for me to continue to shape my honors thesis I will write next year. I will work this week to come up with concrete ways that the three paper I've read relate to and can be used with my honors thesis.
I also explored the NLTK package that was included in my Python 2.7 download to see about the potential of using it to create more complex and in depth language models. However, the more I experimented and looked through documentation for the package, the more I felt like it wasn't the right tool to use. I discussed this with Professor Passonneau and she decided to contact members of the NLP community she knows to try and find a better tool to use.
I also completely finished uploading and organizing all perplexity values into the database so that all values are succinctly stored in one table on the database, with a comment describing what the values are.
Blog #29 - Week of March 29th
This week, Professor Passonneau pointed me to three different papers to read to help get oriented with my thesis topic, which is going to deal with the semantic complexity of questions and the possible correlation between that and the response to the question by a Question Answering system. I spent this week reading 2 out of the 3 papers, jotting down notes and continuing to come up with ideas that could contribute to my thesis.
I also finished uploading all the perplexity values into the database. I need to combine it all into one succinct table, but am not entirely sure how to do that just yet, as there is a nuance with combining two of them that I need to figure out. I plan to talk to Professor Passonneau about that at our meeting tomorrow.
I also began looking into downloading NLTK in order to create higher order language models, but haven't been able to get passed that yet due to it requiring a certain version of Python that I think I have but it can't find. I'm going to look into that more and hopefully find a solution within a couple days.
Blog #28 - Week of March 22nd
I began figuring out how to upload the perplexity values that I've found and stored on my local computer into the database through pgAdmin. This was trickier than expected, as I ran into a lot of different errors that didn't have the most straightforward answers. Professor Passonneau helped, but even how she was doing it wasn't working for me. I have to manually upload each file into the pgAdmin import dialog box, and then I can actually import the file and store it in the appropriate places. Once I figured this out, I was able to upload all of the Free917 data into the database, and this week I will work on doing the rest of them.
I also looked into downloading and using the SRI toolkit in order to create more complex language models, but was having a lot of issues figuring out how to download it to my Windows computer. I showed Professor Passonneau the problems I was having and we decided to switch gears and work with NLTK instead. This week, I will be working on downloading NLTK and creating those language models.
Blog #27 - Week of March 15th
This week, I continued the work I had from last week, as we had a last minute cancellation of our weekly meeting. I mostly worked on getting my honors thesis topic together, so that I could discuss it with Professor Passonneau at next meeting and get that part moving. I also continued to work on aggregating all the perplexity measures I've gotten and bringing them together into one concise table.
Blog #26 - Week of March 8th
I finished all the bootstrap processing that I was doing. I actually found a way for it to happen much quicker than the first couple rounds I did. I realized that I was doing a lot of manual work that wasn't necessary anymore (my assumptions the first couple rounds didn't really apply anymore), and was able to make it run much quicker. When taking a random sample of 1000 questions from SQuAD and WebQuestions, and then repeatedly taking samples of 800 from those 1000, the average perplexity ended up being almost identical to when I took random samples of 800 from the entire data set. This was expected, as 1000 is a large enough number of questions that it should be relatively representative of the entire data set.
I continued to think about my honors thesis as well. I think ideally I would like to create some set of criteria that would help to select questions that meet certain constraints. I want to think more about how I would actually go about this, but it seems like an interesting topic and one I would like to work on.
Blog #25 - Week of March 1st
This week, I was on spring break and got pretty sick, so I was not able to accomplish as much as I had planned. I did think more about what direction I would like to take my Honors Thesis in, as well as do a little more of the bootstrap processing, but not too much.
Blog #24 - Week of February 22nd
I presented my work thus far in our lab meeting this week, so most of my work for this week specifically surrounded getting that presentation ready and making sure I could communicate my work in a clear and concise manner. I discovered the error that caused my bootstrap calculations to be off, which was due to the fact that when I copied the chosen NL questions from the database, the strings got quotation marks added to them. This caused the perplexity measurement to be off because the model was looking for words with those marks when there likely wasn't any/that wasn't even the actual text of the question anyways. I re-ran the SQuAD and Free917 questions and got values for perplexity that made way more sense than my original ones. I was then able to update my presentation with the values and deliver more accurate information to the rest of the lab.
Blog #23 - Week of February 15th
I was supposed to present my work to the lab this week, but due to some deadlines and other circumstances, the meeting was canceled and I rescheduled my presentation for next week. However, I worked heavily on getting the skeleton for my presentation in order and gathering the data for the bootstrapping procedures I wanted to present on. The bootstrapping values I got for Free917 did not make any sense, while the values for SQuAD made some sense but were still not entirely what I expected to see. I discussed the unexpectedness with Professor Passonneau, and she suggested I work through debugging the problem as those values were not only not expected but also were almost certainly wrong. I also spent this week reflecting on my past work, thinking about how far I've come and how to put everything into one cohesive PowerPoint.
Blog #22 - Week of February 8th
This week, I worked on getting the first round of Bootstrapping done. This required a lot more research than I expected, because I had to figure out how to access the database as well as what SQL command to query the database with so I got the information back that I actually wanted to get. I was only able to get through a few samples of the Free917 database, but now that I have a solid procedure for how to actually get the information I need to, I believe that the next few runs will take way less time. I am presenting at our lab meeting next week as well, so I started working on my presentation for that as well.
Blog #21 - Week of February 1st
Professor Passonneau directed me to a paper discussing what a bootstrap interval is, so I spent this week becoming familiar with the process by reading the paper and deciding how I could go about making a bootstrap confidence interval for the percentages of each type of question in the data set. Having become comfortable with the process, and keeping in mind our goal for the semester of trying to switch to using the database for all of our statistical queries, I made sure I could access the database and that the necessary data was already put into the database for use. After confirming all of that, I began to familiarize myself with SQL so that I could accurately execute the needed commands to get the intervals needed.
Blog #20 - Week of January 25th
This week, I continued to assist in the submission of the paper that the lab was working on last week. I completed calculating all the statistics that Professor Passonneau asked for - a lot on the fly, since as the paper became fully developed, more statistics were needed to create a solid paper. After we have our weekly meeting, I will likely get new work to do for the following week on something new.
Blog #19 - Week of January 18th
The NLP lab is working hard to get a paper submitted based on the work primarily done by one graduate student about the use of knowledge graphs and querying. This past week, I assisted in aggregating numerical data about the observations made. I wrote multiple Python scripts to calculate and gather the needed information, as well as was in constant communication with Professor Passonneau for the week to make sure that I was correctly interpreting what that needed data was. This next week, I am extending those calculations to provide more in depth analysis of the results. As the paper deadline approaches, I will need to finish this work by the end of the weekend.
My goal for this week is to not only meet that deadline, but meet it early, so as to provide time to ensure my calculations are accurate and sufficient. My long term goal for this semester is to be published as a supporting author on a paper, as that is a big push for the lab right now and a great opportunity for me to get involved with.
Blog #18 - Week of January 9th
This week I spent reviewing my materials and work done from last semester so that I am ready to go when I meet with Professor Passonneau. My first meeting with her is Thursday the 18th, which is when I will get back into the next steps of my research. I'm looking forward to a new semester, and hopefully making even more progress this semester than I did last.
Blog #17 - Week of January 2nd
No research done - holiday break.
Blog #16 - Week of December 26th
No research done - holiday break.
Blog #15 - Week of December 19th
No research done - holiday break.
Blog #14 - Week of December 12th
No research done - finals preparation and finals week.
Blog #13 - Week of December 5th
This last week of the semester, I made sure the work I had done up to this point in the semester was aptly documented and stored correctly. This way, I will be able to pick right back up with it next semester when I come back to school in January.
Blog #12 - Week of November 28th
As I come closer to the end of this semester, I am tiding up the project so that I have an easy point with which to start from next semester. I have altered the script so that the Question ID is pulled into the POS tagged Excel file (example is seen in PHOTOS section below), which makes the script that extracts the statistics simpler in that it doesn't have to accept two different files as inputs. Having finished the code, I have started creating some documentation so that I have an idea of what the scripts do specifically when I come back to them. I am also working on extracting the perplexity of a number of different questions from each data set being used as another possible statistic to help characterize the complexity of a certain data set. That will also be done before the end of the semester, so I will make sure that that script is annotated well too. I hope that by the end of this semester I have closed up the project nicely so that it is contained and ready for me to come back to next semester. As soon as I get back, I hope to have access to our database and begin directly interacting with the data there. In addition, I hope to be published on some papers in the spring, as both a contributing and lead author.
Blog #11 - Week of November 14th
I continued to work on the script from last week. After meeting with Professor Passonneau, I needed to make a few updates including adding a when category, an other category for every wh-word, and an other category outside of the wh-words. After making those changes and updating the stats for the SQUAD and free917 data sets, I started working on creating an Excel table that holds the question ID, the wh-word category, and the fine-grained wh-word category. I ran into issues quickly in trying to edit an existing Excel worksheet in Pycharm, and am had to do some work around to get those fixed. However, I was able to create an Excel table with the three columns as needed (shown in PHOTOS section below). Each script runs very quickly as well, even for the large SQUAD data set, so I don't foresee any performance issues with the script even as the data sets get larger.
I do not know exactly what is next, but I hope that I can start to work with the database and get to see my script in action in populating the tables in the database with these meaningful values. In the longer term, it's my goal to have started interacting with the database itself by the end of the semester, enough so that I have a solid understanding of how it works. That way, I can start next semester strong and work entirely with that database instead of my local computer.
Blog #10 - Week of November 7th
This week I completely fixed the script for processing the data sets and ran it on both the SQUAD data set and the Free917 data set. I outputted many different figures, including the total number of types of question - what, who, where, how, which, questions starting with a preposition and questions starting with to - to a text file so we can look at it (this output is in the PHOTOS section below). In my meeting with Professor Passonneau, I will go over these figures and discuss what further processing should be done. The processing was not complete for either data set, meaning that it did not catch all possible question types represented in the set (seen because the total number of question types processed did not equal the total number of questions in the data set). This coming week, I hope to fully process everything, capturing all types of questions in order to provide a fuller analysis of the data set. I am also going to start coming up with question categories for data sets to indicate complexity. I hope to soon be able to run this script on more and more data sets, so that I can see the differences across many different sets and evaluate what that means in terms of our project as well as in terms of Question Answering Systems as a whole.
Blog #9 - Week of October 31st
This week, I began to fix the script I have written for processing the different data sets that I am using (right now, is just the free917 and squad data sets). I ran into an error rather quickly where when I wrote out data to a text file, it would change all the types of the variables to be strings. This makes reading the data back in and trying to process it a much harder task since I would have to manually look through and parse the string for the different sequences of POS. I didn't think this was the best way to go about it, so I talked with Professor Passonneau, and I decided to output the processed text into an Excel file to better format the data I need. This week I will be putting in a lot of work to get the data for the free917 and squad data sets parsed and counted as needed so Professor Passonneau and I can analyze them at our next meeting.
Blog #8 - Week of October 24th
This week, Professor Passonneau gave me two readings to look and see how they pertain to our research, both dealing with question answering systems from an educational standpoint. The first, by Nielsen et al, is titled "A Taxonomy of Questions for Question Generation". I found this read particularly interesting because it seemed as though the intent the taxonomy fits very nicely with what our research is. The work Nielsen and company did is on the other side of what we are trying to do, in that they are working to create a system that generates appropriate questions based on a user answer, while we are working to create a system that generates appropriate answers to questions. Our two systems could easily combine into one that facilitated meaningful conversations rather than just simple questions with simple yes/no answers.
The other paper I read is titled "Question Asking During Tutoring," and it discusses the lack of student questions seen in the classroom versus the amount of questions during tutoring, exploring different ideas about how that effects how a student learns the given material. I did not get to read this paper very in-depth, and so would like to go back to it and re-read it to really digest the full meaning of what it is saying. This paper also lines up with our research in that given the questions asked during tutoring, our system that we are working to create would hopefully be able to answer these more meaningfully and help facilitate the student actually learning the material.
In the next week, I want to really digest this and consider the implications our own research has in the realm of education. In the future, once the system is complete, I would be curious to see the resulting effects on tutoring sessions and more.
Blog #7 - Week of October 17th
This week, I was able to access the database that is now being hosted on pgAdmin4 instead of Navicat. It was a simple, straightforward process which was a nice change from trying to access it using Navicat last week. I also gathered simple typological statistics for both the free917 data set and the SQUAD data set, including total number of words, total number of questions and total number of unique words (a screenshot of this output is below in the PHOTOS section). I also created a python program that uses the Stanford POS tagger to tag each word in each question of whichever data set you would like by specifying a path to the data set stored on my local computer. It is a little buggy currently, and repeats some calculations which is unnecessary, so I will be modifying/debugging that this week to get it to run as it should. This week, my goal is to complete that program as well as read and take notes on both of the articles Professor Passonneau placed in my box. I hope to soon see my code actually interacting with the database information, and work to make it able to take in multiple different types of input instead of just a JSON file.
Blog #6 - Week of October 10th
I began this week to try to access the Virtuoso database that the NLP lab is using to store the knowledge base using a GUI called Navicat. This GUI turned out to not be effective for our purposes, and this week I will be working with a different interface to access the database (PostGres/PgAdminDo). Last week I also wrote a python script that would take in the JSON file of the parsed output from SQUAD and do basic textual analysis. The script counts up the total number of words in the entire set, as well as counts the frequency of each word seen in the questions. My goal this week is to improve the script to output more basic values about the text as well as analyze these numbers to come up with some kind of attribute set for the complexity of the data set. In addition, I began to use Linux to process a text file containing the Free917 data set, focused mostly on categorizing question type and seeing if there were natural splits of complexity among these categories. I will continue this work next week. My other goal for next week is to complete both of these analyses on both SQUAD and Free917 (so run Free917 using the python script and do Linux processing on SQUAD). In the long term, I hope to come up with succinct and clear categories to describe the complexity of data sets.
Blog #5 - Week of October 3rd
This week I was working on coming up with a set of attributes to describe an arbitrary question data set, using the free917 data set. I will be continuing with this work this week, as I was set back by the process of getting access to the data set itself. This week, I hope to get through the entire free917 data set as well as the SQUAD data set, and begin to make concrete progress towards coming up with those attributes. In addition, I am still working with my local database management studio to take in a JSON file and be able to count up the entries of a certain key in the file. I was running into an error of a column not existing in the database table, despite the fact that I could verify that the column did exist. I will be working with this error this week, and hope to get it resolved so I can have a smooth transition to the real database manager I will use.
In the long term, I'm looking forward to seeing how my skills I'm learning with the database manager on my local computer will transfer to the real database we are using. This week I am also going to get the GUI for the real database downloaded and set up on my computer, so I will be beginning to make progress towards working with the database quite soon.
Blog #4 - Week of September 26th
After meeting with Professor Passonneau last week, we decided to go in a different direction with the database management I was doing. Using the MySQL Workbench was proving to be more difficult than was intended or necessary, so I scrapped that and downloaded Microsoft SQL Server instead after researching more about what SQL server software works best on Windows 10. This software has been much easier to work with and more along the lines of what we need. Just this week, I have already been able create a database with a Question table within it, as well as take information in the JSON file on my local computer and pipe it directly to the database table in the correct column. The next step is to figure out how best to count up the number of items in a category of the JSON file using Python, so that the rest of the information in the JSON file can be uploaded to the database. This week, I hope to figure that out as well as get the updated JSON file so I can work with the complete JSON file and getting that information into the database accurately. In the long term, I hope to access the database we are actually going to use for the project and begin to work with that interface.
Blog #3 - Week of September 19th
This week, my work on the project involved switching how I was dealing with the database management, meaning I stopped using MySQL Workbench and started playing around with traditional MySQL through the command line. Professor Passonneau and I realized that using the MySQL Workbench was causing more issues than it was helping, as it seems to be a software for designing models and creating schemas easily for databases, but we already have a schema in place.
I was having issues trying to figure out whether I can access MySQL through the MySQL Workbench that I downloaded, or whether I had to download a new version. I also tried to see if there was a MySQL version I could download off the internet, but everything installer I came across was for the whole workbench and not just the MySQL language. I want to iron out this problem in the coming week, and hopefully actually get to interact with MySQL and a database. I hope that I will be able to transfer these skills I learn by interacting with MySQL in this way to the database manager that the NLP lab uses as well.
Blog #2 - Week of September 12th
After my meeting with Professor Passonneau last week, I realized I was thinking about the goal of this part of my project wrong. The ultimate goal is for me to provide transitions between a json file that contains all the data for the database and a tab separated text file as well as between the text file and the database itself. This means I am to work on a python script to take in a json file and read in the data from the json file into a tab separated text file that mimics the structure of the database. Then, I am to come up with a way for the tab separated text file to be uploaded into the corresponding database tables in one command.
This week, I began to work on the python script to take in the json file and output the information to a text file. I currently am only extracting the natural language question and the question ID and putting these values into the text file. However, I am able to successfully do this and can see the values in the text file. The next step is to add all the values into the text file in a tab separated list.
I have also been investigating a problem I encountered when I tried to forward engineer my database. I think the issue has to do with the connection to the server, so today I am going to investigate that problem and see what I can find out. While that is being solved, I have also begun to experiment with different SQL commands using an already instantiated database in MySQL Workbench.
Blog #1 - Week of September 5th
This week, as one of my first weeks getting back into the project, I have picked up right where I left off in the spring and begun to delve into the first objective of what is outlined on my project proposal – “Develop a rich dataset for automated question-answering that will facilitate comparison of the research challenges presented by different kinds of questions with respect to two kinds of knowledge sources, textual and RDF.” In the spring, I was working more with the actual data, getting familiar with the categorization of that data as well as learning how best to store the different values in meaningful tables. I proposed a schema for storing the data, which was finalized over the summer.
This fall, I have started to shift away from interacting with the actual data and begun to investigate ways to store that data. This past week, I downloaded a software called MySQL Workbench as a potential candidate to create the database and store the data. I initialized the database with a few of the different values that the other students have created following the given schema, which are stored in a json file Professor Passonneau shared with me.
This week, I have been looking more into the software and how it works to give me a better idea of the use for this project. After my first meeting with Professor Passonneau, she noted that the goal is for the process of updating and adding to the database to be automatic (something that seems obvious, but I had actually overlooked). What I have found pertaining to the software and its ability to automate database population is promising. The workbench software essentially allows one to create a model of the data to be stored in the database (using tables), and then connect to a server (either locally or remotely) and run data through the model to be stored in the database. This process is what is called “forward engineering” in the MySQL Workbench Manual.
What I’m curious about as I think about the potential of the software to be what we use to store the data is the ability to move the control of the process off of my local computer and onto someone else’s machine. From my initial cursory search, I know I can connect to a remote server using specific server settings within the software and SSH, but I do not know if it will be possible for me to transfer the control of updating the database to someone else. This is something I will bring up with Professor Passonneau in our next meeting, as I am still unsure of exactly what the intent is for the hosting and control of the database.
Despite this uncertainty, I am moving forward with this software and attempting to do my first forward engineering. I believe the software would work out exactly as it needs to if this last hiccup pans out. The goal for this week is to figure out how to “forward engineer” the data to actually create the database. To start right from square one, I am going to manually populate the tables with some of the data (which creates a schema of a small part of the data) and then try to connect it to a server to actually create the database. I will choose data that fill most (if not all) of the table columns so as to get a very good sense of what a complete entry should look like and how the creation of the database will go with a full entry. The ultimate goal I am working towards by accomplishing this small task is to decide whether the software is what we want ot use to store all the data we are going to need to store.
I am excited to see the results of this forward engineering, and hope that the software works out like we need it to.
I read the third paper that Professor Passonneau pointed me to this week. It was a hefty paper and I will likely have to go back through it to fully understand all parts, but it presented good material for me to continue to shape my honors thesis I will write next year. I will work this week to come up with concrete ways that the three paper I've read relate to and can be used with my honors thesis.
I also explored the NLTK package that was included in my Python 2.7 download to see about the potential of using it to create more complex and in depth language models. However, the more I experimented and looked through documentation for the package, the more I felt like it wasn't the right tool to use. I discussed this with Professor Passonneau and she decided to contact members of the NLP community she knows to try and find a better tool to use.
I also completely finished uploading and organizing all perplexity values into the database so that all values are succinctly stored in one table on the database, with a comment describing what the values are.
Blog #29 - Week of March 29th
This week, Professor Passonneau pointed me to three different papers to read to help get oriented with my thesis topic, which is going to deal with the semantic complexity of questions and the possible correlation between that and the response to the question by a Question Answering system. I spent this week reading 2 out of the 3 papers, jotting down notes and continuing to come up with ideas that could contribute to my thesis.
I also finished uploading all the perplexity values into the database. I need to combine it all into one succinct table, but am not entirely sure how to do that just yet, as there is a nuance with combining two of them that I need to figure out. I plan to talk to Professor Passonneau about that at our meeting tomorrow.
I also began looking into downloading NLTK in order to create higher order language models, but haven't been able to get passed that yet due to it requiring a certain version of Python that I think I have but it can't find. I'm going to look into that more and hopefully find a solution within a couple days.
Blog #28 - Week of March 22nd
I began figuring out how to upload the perplexity values that I've found and stored on my local computer into the database through pgAdmin. This was trickier than expected, as I ran into a lot of different errors that didn't have the most straightforward answers. Professor Passonneau helped, but even how she was doing it wasn't working for me. I have to manually upload each file into the pgAdmin import dialog box, and then I can actually import the file and store it in the appropriate places. Once I figured this out, I was able to upload all of the Free917 data into the database, and this week I will work on doing the rest of them.
I also looked into downloading and using the SRI toolkit in order to create more complex language models, but was having a lot of issues figuring out how to download it to my Windows computer. I showed Professor Passonneau the problems I was having and we decided to switch gears and work with NLTK instead. This week, I will be working on downloading NLTK and creating those language models.
Blog #27 - Week of March 15th
This week, I continued the work I had from last week, as we had a last minute cancellation of our weekly meeting. I mostly worked on getting my honors thesis topic together, so that I could discuss it with Professor Passonneau at next meeting and get that part moving. I also continued to work on aggregating all the perplexity measures I've gotten and bringing them together into one concise table.
Blog #26 - Week of March 8th
I finished all the bootstrap processing that I was doing. I actually found a way for it to happen much quicker than the first couple rounds I did. I realized that I was doing a lot of manual work that wasn't necessary anymore (my assumptions the first couple rounds didn't really apply anymore), and was able to make it run much quicker. When taking a random sample of 1000 questions from SQuAD and WebQuestions, and then repeatedly taking samples of 800 from those 1000, the average perplexity ended up being almost identical to when I took random samples of 800 from the entire data set. This was expected, as 1000 is a large enough number of questions that it should be relatively representative of the entire data set.
I continued to think about my honors thesis as well. I think ideally I would like to create some set of criteria that would help to select questions that meet certain constraints. I want to think more about how I would actually go about this, but it seems like an interesting topic and one I would like to work on.
Blog #25 - Week of March 1st
This week, I was on spring break and got pretty sick, so I was not able to accomplish as much as I had planned. I did think more about what direction I would like to take my Honors Thesis in, as well as do a little more of the bootstrap processing, but not too much.
Blog #24 - Week of February 22nd
I presented my work thus far in our lab meeting this week, so most of my work for this week specifically surrounded getting that presentation ready and making sure I could communicate my work in a clear and concise manner. I discovered the error that caused my bootstrap calculations to be off, which was due to the fact that when I copied the chosen NL questions from the database, the strings got quotation marks added to them. This caused the perplexity measurement to be off because the model was looking for words with those marks when there likely wasn't any/that wasn't even the actual text of the question anyways. I re-ran the SQuAD and Free917 questions and got values for perplexity that made way more sense than my original ones. I was then able to update my presentation with the values and deliver more accurate information to the rest of the lab.
Blog #23 - Week of February 15th
I was supposed to present my work to the lab this week, but due to some deadlines and other circumstances, the meeting was canceled and I rescheduled my presentation for next week. However, I worked heavily on getting the skeleton for my presentation in order and gathering the data for the bootstrapping procedures I wanted to present on. The bootstrapping values I got for Free917 did not make any sense, while the values for SQuAD made some sense but were still not entirely what I expected to see. I discussed the unexpectedness with Professor Passonneau, and she suggested I work through debugging the problem as those values were not only not expected but also were almost certainly wrong. I also spent this week reflecting on my past work, thinking about how far I've come and how to put everything into one cohesive PowerPoint.
Blog #22 - Week of February 8th
This week, I worked on getting the first round of Bootstrapping done. This required a lot more research than I expected, because I had to figure out how to access the database as well as what SQL command to query the database with so I got the information back that I actually wanted to get. I was only able to get through a few samples of the Free917 database, but now that I have a solid procedure for how to actually get the information I need to, I believe that the next few runs will take way less time. I am presenting at our lab meeting next week as well, so I started working on my presentation for that as well.
Blog #21 - Week of February 1st
Professor Passonneau directed me to a paper discussing what a bootstrap interval is, so I spent this week becoming familiar with the process by reading the paper and deciding how I could go about making a bootstrap confidence interval for the percentages of each type of question in the data set. Having become comfortable with the process, and keeping in mind our goal for the semester of trying to switch to using the database for all of our statistical queries, I made sure I could access the database and that the necessary data was already put into the database for use. After confirming all of that, I began to familiarize myself with SQL so that I could accurately execute the needed commands to get the intervals needed.
Blog #20 - Week of January 25th
This week, I continued to assist in the submission of the paper that the lab was working on last week. I completed calculating all the statistics that Professor Passonneau asked for - a lot on the fly, since as the paper became fully developed, more statistics were needed to create a solid paper. After we have our weekly meeting, I will likely get new work to do for the following week on something new.
Blog #19 - Week of January 18th
The NLP lab is working hard to get a paper submitted based on the work primarily done by one graduate student about the use of knowledge graphs and querying. This past week, I assisted in aggregating numerical data about the observations made. I wrote multiple Python scripts to calculate and gather the needed information, as well as was in constant communication with Professor Passonneau for the week to make sure that I was correctly interpreting what that needed data was. This next week, I am extending those calculations to provide more in depth analysis of the results. As the paper deadline approaches, I will need to finish this work by the end of the weekend.
My goal for this week is to not only meet that deadline, but meet it early, so as to provide time to ensure my calculations are accurate and sufficient. My long term goal for this semester is to be published as a supporting author on a paper, as that is a big push for the lab right now and a great opportunity for me to get involved with.
Blog #18 - Week of January 9th
This week I spent reviewing my materials and work done from last semester so that I am ready to go when I meet with Professor Passonneau. My first meeting with her is Thursday the 18th, which is when I will get back into the next steps of my research. I'm looking forward to a new semester, and hopefully making even more progress this semester than I did last.
Blog #17 - Week of January 2nd
No research done - holiday break.
Blog #16 - Week of December 26th
No research done - holiday break.
Blog #15 - Week of December 19th
No research done - holiday break.
Blog #14 - Week of December 12th
No research done - finals preparation and finals week.
Blog #13 - Week of December 5th
This last week of the semester, I made sure the work I had done up to this point in the semester was aptly documented and stored correctly. This way, I will be able to pick right back up with it next semester when I come back to school in January.
Blog #12 - Week of November 28th
As I come closer to the end of this semester, I am tiding up the project so that I have an easy point with which to start from next semester. I have altered the script so that the Question ID is pulled into the POS tagged Excel file (example is seen in PHOTOS section below), which makes the script that extracts the statistics simpler in that it doesn't have to accept two different files as inputs. Having finished the code, I have started creating some documentation so that I have an idea of what the scripts do specifically when I come back to them. I am also working on extracting the perplexity of a number of different questions from each data set being used as another possible statistic to help characterize the complexity of a certain data set. That will also be done before the end of the semester, so I will make sure that that script is annotated well too. I hope that by the end of this semester I have closed up the project nicely so that it is contained and ready for me to come back to next semester. As soon as I get back, I hope to have access to our database and begin directly interacting with the data there. In addition, I hope to be published on some papers in the spring, as both a contributing and lead author.
Blog #11 - Week of November 14th
I continued to work on the script from last week. After meeting with Professor Passonneau, I needed to make a few updates including adding a when category, an other category for every wh-word, and an other category outside of the wh-words. After making those changes and updating the stats for the SQUAD and free917 data sets, I started working on creating an Excel table that holds the question ID, the wh-word category, and the fine-grained wh-word category. I ran into issues quickly in trying to edit an existing Excel worksheet in Pycharm, and am had to do some work around to get those fixed. However, I was able to create an Excel table with the three columns as needed (shown in PHOTOS section below). Each script runs very quickly as well, even for the large SQUAD data set, so I don't foresee any performance issues with the script even as the data sets get larger.
I do not know exactly what is next, but I hope that I can start to work with the database and get to see my script in action in populating the tables in the database with these meaningful values. In the longer term, it's my goal to have started interacting with the database itself by the end of the semester, enough so that I have a solid understanding of how it works. That way, I can start next semester strong and work entirely with that database instead of my local computer.
Blog #10 - Week of November 7th
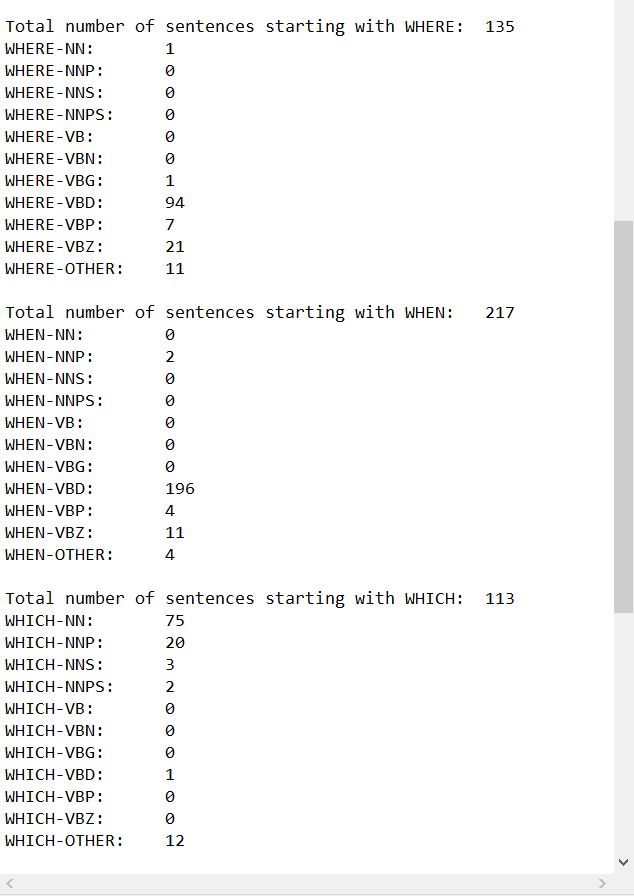
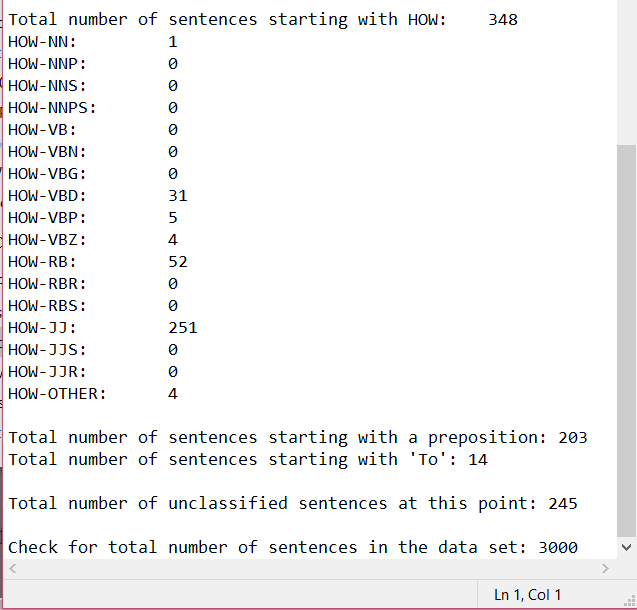
This week I completely fixed the script for processing the data sets and ran it on both the SQUAD data set and the Free917 data set. I outputted many different figures, including the total number of types of question - what, who, where, how, which, questions starting with a preposition and questions starting with to - to a text file so we can look at it (this output is in the PHOTOS section below). In my meeting with Professor Passonneau, I will go over these figures and discuss what further processing should be done. The processing was not complete for either data set, meaning that it did not catch all possible question types represented in the set (seen because the total number of question types processed did not equal the total number of questions in the data set). This coming week, I hope to fully process everything, capturing all types of questions in order to provide a fuller analysis of the data set. I am also going to start coming up with question categories for data sets to indicate complexity. I hope to soon be able to run this script on more and more data sets, so that I can see the differences across many different sets and evaluate what that means in terms of our project as well as in terms of Question Answering Systems as a whole.
Blog #9 - Week of October 31st
This week, I began to fix the script I have written for processing the different data sets that I am using (right now, is just the free917 and squad data sets). I ran into an error rather quickly where when I wrote out data to a text file, it would change all the types of the variables to be strings. This makes reading the data back in and trying to process it a much harder task since I would have to manually look through and parse the string for the different sequences of POS. I didn't think this was the best way to go about it, so I talked with Professor Passonneau, and I decided to output the processed text into an Excel file to better format the data I need. This week I will be putting in a lot of work to get the data for the free917 and squad data sets parsed and counted as needed so Professor Passonneau and I can analyze them at our next meeting.
Blog #8 - Week of October 24th
This week, Professor Passonneau gave me two readings to look and see how they pertain to our research, both dealing with question answering systems from an educational standpoint. The first, by Nielsen et al, is titled "A Taxonomy of Questions for Question Generation". I found this read particularly interesting because it seemed as though the intent the taxonomy fits very nicely with what our research is. The work Nielsen and company did is on the other side of what we are trying to do, in that they are working to create a system that generates appropriate questions based on a user answer, while we are working to create a system that generates appropriate answers to questions. Our two systems could easily combine into one that facilitated meaningful conversations rather than just simple questions with simple yes/no answers.
The other paper I read is titled "Question Asking During Tutoring," and it discusses the lack of student questions seen in the classroom versus the amount of questions during tutoring, exploring different ideas about how that effects how a student learns the given material. I did not get to read this paper very in-depth, and so would like to go back to it and re-read it to really digest the full meaning of what it is saying. This paper also lines up with our research in that given the questions asked during tutoring, our system that we are working to create would hopefully be able to answer these more meaningfully and help facilitate the student actually learning the material.
In the next week, I want to really digest this and consider the implications our own research has in the realm of education. In the future, once the system is complete, I would be curious to see the resulting effects on tutoring sessions and more.
Blog #7 - Week of October 17th
This week, I was able to access the database that is now being hosted on pgAdmin4 instead of Navicat. It was a simple, straightforward process which was a nice change from trying to access it using Navicat last week. I also gathered simple typological statistics for both the free917 data set and the SQUAD data set, including total number of words, total number of questions and total number of unique words (a screenshot of this output is below in the PHOTOS section). I also created a python program that uses the Stanford POS tagger to tag each word in each question of whichever data set you would like by specifying a path to the data set stored on my local computer. It is a little buggy currently, and repeats some calculations which is unnecessary, so I will be modifying/debugging that this week to get it to run as it should. This week, my goal is to complete that program as well as read and take notes on both of the articles Professor Passonneau placed in my box. I hope to soon see my code actually interacting with the database information, and work to make it able to take in multiple different types of input instead of just a JSON file.
Blog #6 - Week of October 10th
I began this week to try to access the Virtuoso database that the NLP lab is using to store the knowledge base using a GUI called Navicat. This GUI turned out to not be effective for our purposes, and this week I will be working with a different interface to access the database (PostGres/PgAdminDo). Last week I also wrote a python script that would take in the JSON file of the parsed output from SQUAD and do basic textual analysis. The script counts up the total number of words in the entire set, as well as counts the frequency of each word seen in the questions. My goal this week is to improve the script to output more basic values about the text as well as analyze these numbers to come up with some kind of attribute set for the complexity of the data set. In addition, I began to use Linux to process a text file containing the Free917 data set, focused mostly on categorizing question type and seeing if there were natural splits of complexity among these categories. I will continue this work next week. My other goal for next week is to complete both of these analyses on both SQUAD and Free917 (so run Free917 using the python script and do Linux processing on SQUAD). In the long term, I hope to come up with succinct and clear categories to describe the complexity of data sets.
Blog #5 - Week of October 3rd
This week I was working on coming up with a set of attributes to describe an arbitrary question data set, using the free917 data set. I will be continuing with this work this week, as I was set back by the process of getting access to the data set itself. This week, I hope to get through the entire free917 data set as well as the SQUAD data set, and begin to make concrete progress towards coming up with those attributes. In addition, I am still working with my local database management studio to take in a JSON file and be able to count up the entries of a certain key in the file. I was running into an error of a column not existing in the database table, despite the fact that I could verify that the column did exist. I will be working with this error this week, and hope to get it resolved so I can have a smooth transition to the real database manager I will use.
In the long term, I'm looking forward to seeing how my skills I'm learning with the database manager on my local computer will transfer to the real database we are using. This week I am also going to get the GUI for the real database downloaded and set up on my computer, so I will be beginning to make progress towards working with the database quite soon.
Blog #4 - Week of September 26th
After meeting with Professor Passonneau last week, we decided to go in a different direction with the database management I was doing. Using the MySQL Workbench was proving to be more difficult than was intended or necessary, so I scrapped that and downloaded Microsoft SQL Server instead after researching more about what SQL server software works best on Windows 10. This software has been much easier to work with and more along the lines of what we need. Just this week, I have already been able create a database with a Question table within it, as well as take information in the JSON file on my local computer and pipe it directly to the database table in the correct column. The next step is to figure out how best to count up the number of items in a category of the JSON file using Python, so that the rest of the information in the JSON file can be uploaded to the database. This week, I hope to figure that out as well as get the updated JSON file so I can work with the complete JSON file and getting that information into the database accurately. In the long term, I hope to access the database we are actually going to use for the project and begin to work with that interface.
Blog #3 - Week of September 19th
This week, my work on the project involved switching how I was dealing with the database management, meaning I stopped using MySQL Workbench and started playing around with traditional MySQL through the command line. Professor Passonneau and I realized that using the MySQL Workbench was causing more issues than it was helping, as it seems to be a software for designing models and creating schemas easily for databases, but we already have a schema in place.
I was having issues trying to figure out whether I can access MySQL through the MySQL Workbench that I downloaded, or whether I had to download a new version. I also tried to see if there was a MySQL version I could download off the internet, but everything installer I came across was for the whole workbench and not just the MySQL language. I want to iron out this problem in the coming week, and hopefully actually get to interact with MySQL and a database. I hope that I will be able to transfer these skills I learn by interacting with MySQL in this way to the database manager that the NLP lab uses as well.
Blog #2 - Week of September 12th
After my meeting with Professor Passonneau last week, I realized I was thinking about the goal of this part of my project wrong. The ultimate goal is for me to provide transitions between a json file that contains all the data for the database and a tab separated text file as well as between the text file and the database itself. This means I am to work on a python script to take in a json file and read in the data from the json file into a tab separated text file that mimics the structure of the database. Then, I am to come up with a way for the tab separated text file to be uploaded into the corresponding database tables in one command.
This week, I began to work on the python script to take in the json file and output the information to a text file. I currently am only extracting the natural language question and the question ID and putting these values into the text file. However, I am able to successfully do this and can see the values in the text file. The next step is to add all the values into the text file in a tab separated list.
I have also been investigating a problem I encountered when I tried to forward engineer my database. I think the issue has to do with the connection to the server, so today I am going to investigate that problem and see what I can find out. While that is being solved, I have also begun to experiment with different SQL commands using an already instantiated database in MySQL Workbench.
Blog #1 - Week of September 5th
This week, as one of my first weeks getting back into the project, I have picked up right where I left off in the spring and begun to delve into the first objective of what is outlined on my project proposal – “Develop a rich dataset for automated question-answering that will facilitate comparison of the research challenges presented by different kinds of questions with respect to two kinds of knowledge sources, textual and RDF.” In the spring, I was working more with the actual data, getting familiar with the categorization of that data as well as learning how best to store the different values in meaningful tables. I proposed a schema for storing the data, which was finalized over the summer.
This fall, I have started to shift away from interacting with the actual data and begun to investigate ways to store that data. This past week, I downloaded a software called MySQL Workbench as a potential candidate to create the database and store the data. I initialized the database with a few of the different values that the other students have created following the given schema, which are stored in a json file Professor Passonneau shared with me.
This week, I have been looking more into the software and how it works to give me a better idea of the use for this project. After my first meeting with Professor Passonneau, she noted that the goal is for the process of updating and adding to the database to be automatic (something that seems obvious, but I had actually overlooked). What I have found pertaining to the software and its ability to automate database population is promising. The workbench software essentially allows one to create a model of the data to be stored in the database (using tables), and then connect to a server (either locally or remotely) and run data through the model to be stored in the database. This process is what is called “forward engineering” in the MySQL Workbench Manual.
What I’m curious about as I think about the potential of the software to be what we use to store the data is the ability to move the control of the process off of my local computer and onto someone else’s machine. From my initial cursory search, I know I can connect to a remote server using specific server settings within the software and SSH, but I do not know if it will be possible for me to transfer the control of updating the database to someone else. This is something I will bring up with Professor Passonneau in our next meeting, as I am still unsure of exactly what the intent is for the hosting and control of the database.
Despite this uncertainty, I am moving forward with this software and attempting to do my first forward engineering. I believe the software would work out exactly as it needs to if this last hiccup pans out. The goal for this week is to figure out how to “forward engineer” the data to actually create the database. To start right from square one, I am going to manually populate the tables with some of the data (which creates a schema of a small part of the data) and then try to connect it to a server to actually create the database. I will choose data that fill most (if not all) of the table columns so as to get a very good sense of what a complete entry should look like and how the creation of the database will go with a full entry. The ultimate goal I am working towards by accomplishing this small task is to decide whether the software is what we want ot use to store all the data we are going to need to store.
I am excited to see the results of this forward engineering, and hope that the software works out like we need it to.
PHOTOS
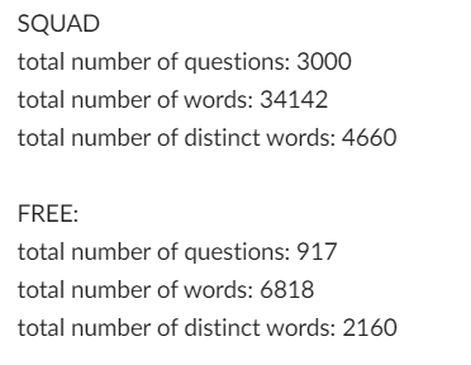
Blog #7 - Statistics gathered
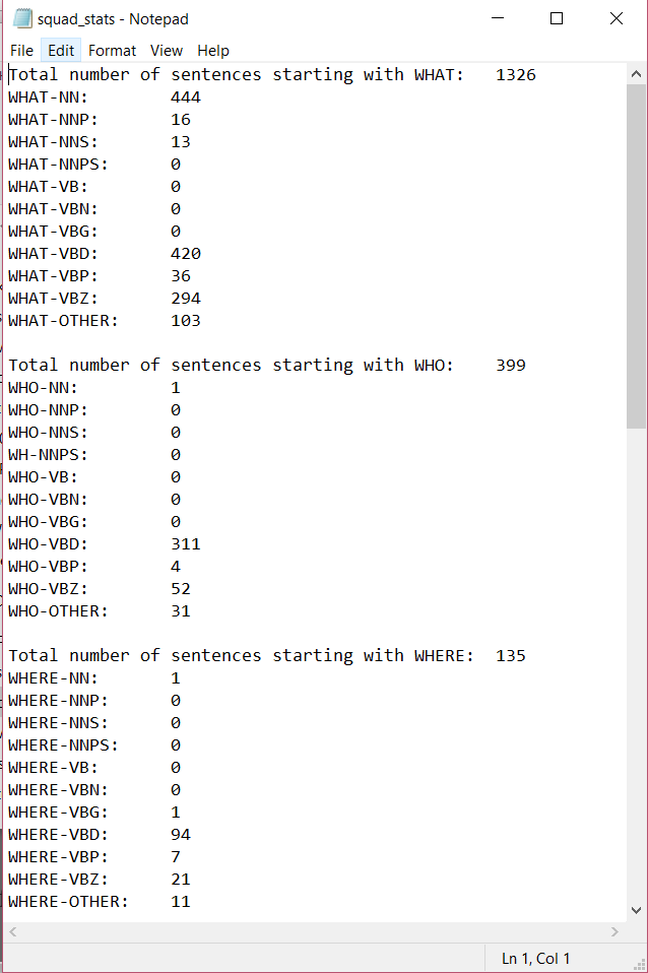
Blog #10 - Statistics gathered
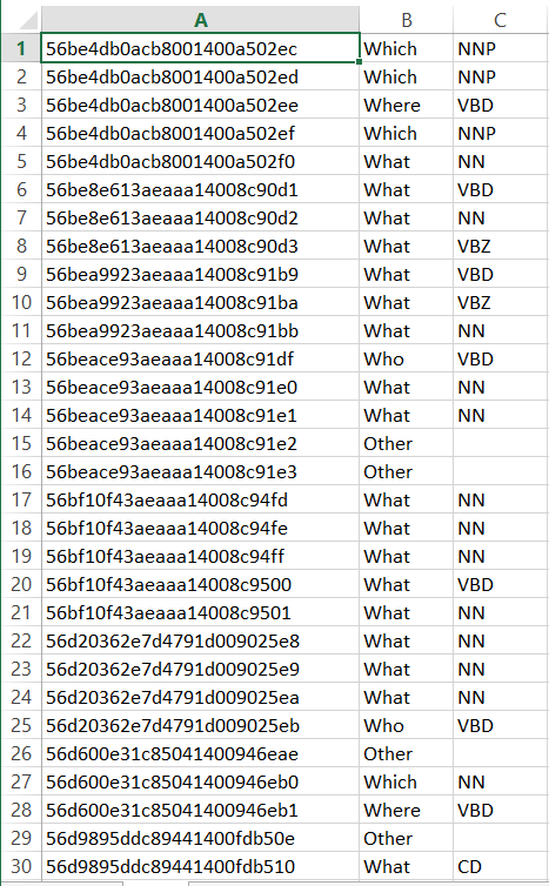
Blog #11 - Three column table
Blog #12 - POS tagged file example
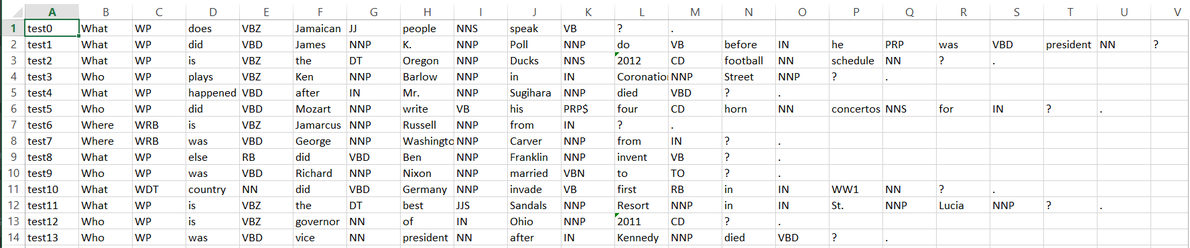
reflections
Challenges:
Excitements:
- Ramping up - understanding the project as a whole and my role within it
- Dealing with database managers - whole area of computer science that I wasn't familiar with, difficult to introduce myself to it
- Dealing with setbacks - always frustrating to put time into one area, only to completely switch courses the next week and all the work you did becomes null
Excitements:
- Determining a question typology - exciting to be leading the charge on an idea that hasn't been introduced to the NLP community yet
- Getting closer and closer to working with the Penn State NLP database as opposed to just my local computer
- Potential to be published as both a contributing author and lead author
